2023年 → 2024年

前回の投稿が 2022年 → 2023年 だったので、だんだん一年の総評をまとめる生存報告ブログになってきています。ちょっと早いですが今年はすでに仕事納めもしており、2023年を締めていきたいと思います。
2023年振り返り
💼 仕事
引き続き Ubie でエンジニアをやらせてもらっています。
バックエンドプロダクト開発多し
仕事内容としては2022年に引き続き、バックエンドのプロダクト開発が多かった年になりました。社内のリスク低減に関連した取り組みではあったのですが、直接的に情報セキュリティに関係があったかというとあんまりなかったです。とはいえ企業におけるリスクというのは情報セキュリティだけに限ったものではありませんし、多角的な経験ができたとも言えます。
また、自分のチームで開発するだけでなく、ほかチームを巻き込む形でプロダクト開発するということもありました。今まで開発といえばほとんど個人技だった自分からすると、この2年間はかなり多くのことを得られたと思っています。実際には何事も「言うは易く行うは難し」でいろいろ苦労も多かったのですが、なかなか良い経験になりました。
とはいえそろそろセキュリティに直接関連するところに戻りたいなと考えており、来年はそちらの方面を全力投球する予定になっています。
組織の変化・進化
Ubieで働き始めてから2年半弱経ったのですが、思い返してみると物凄い勢いで組織が変化してきたのを感じます。入社当時はまだ事業の探索フェーズだったと言ってよく、様々な可能性を模索したり、ときに筋肉運用で物事を解決したりというのも珍しくありませんでした。セキュリティ観点でも最低限の部分を抑えつつ、その他の部分は流動的に対応するというような状況も多くありました。
しかしこの2年半の間で会社として様々な出来事や挑戦があり、その度に組織全体、そして社のメンバーも目覚ましくアップデートしてきていると感じています。特に事業の蓋然性が高くなってきたことにより、会社全体として開発生産性や信頼性をかなり重要視するようになり、それがメンバーにも浸透していったように思います。こういったスタートアップのフェーズの移り変わりというのを経験するのが初めてなので、一般的にこの変化の良し悪し判断が難しいですが、個人的にはわりと凄いことなのではないかなと考えてます。
🌴 趣味
OSS
相変わらず休日はコード書きを趣味にして生きています。2023年のヒット作(当社比)はGoの公式構造化ロガーとして登場した log/slog 利用時に秘匿値をログに出力しないようにする masq かなと思います。
user := struct { ID string Email EmailAddr // ここでは独自の型を使う例(実態はstring型) }{ ID: "u123", Email: "mizutani@hey.com", } // slogのlogger作成時に、ReplaceAttrに指定 logger := slog.New(slog.HandlerOptions{ ReplaceAttr: masq.New(masq.WithType[EmailAddr]()), }.NewJSONHandler(os.Stdout)) // で出力する logger.Info("hello", slog.Any("user", user))
こんな感じでメールアドレスの型を指定すると、
{
"time": "2022-12-25T09:00:00.123456789",
"level": "INFO",
"msg": "hello",
"user": {
"ID": "u123",
"Email": "[REDACTED]"
}
}
こんな感じにメールアドレスの値の部分をフィルタしてくれます。秘匿値がうっかり本番環境のログにでていたときに面倒臭さは何度も体験しているので、(自分で言うのもなんですが)もはや手放せないツールになっています。
あとは軽量SOAR(Security Orchestration, Automation and Response)ツールである AlertChain の開発もかなり力を入れてやってきました。
平たく言うと、いろんな種類のセキュリティアラートをHTTP APIで受け取って、アラートの整形や各種サービスへの連携(情報収集や通知など)を Rego で記述したポリシーをもとに処理してくれるツールです。ポリシーをテキスト形式で記述できるのでGitなどで管理しやすいこと、そしてアラート処理のワークフローを回帰テストできるようになっているのが推しポイントで、個人的には気に入っています。
こちらはすでに社内に展開し利用もしているのですが、まだいろいろ拡張をしたいのと、ユーザ層がかなりニッチだろうと予想しているため、あまり積極的に広報はしていません(何かの発表ではちょろっと話した気がするけど)。もし詳細を知りたいという奇特な方が世の中に1人でもいたら、解説記事の執筆などを前向きに検討したいと思いますので、ぜひご一報ください。
ゲーム
いままでずっとFGOをわりとやっていたんですが、今は完全に原神にドはまりしてます。戦闘システムやキャラの性質を考えた編成の組み方が幅広く、戦略的にいろんな編成で遊べるのが楽しいですね。戦闘の難易度もほどほどの難しさではありつつも奥が深く、エンドコンテンツである深境螺旋をよく遊んでいます。

昨年に引き続き、サイクリングマシンで運動しながら素材収集するというのをほぼ毎日やっており、ゲームをするほど健康になっていてお得です。
2024年どうするか
仕事
ちょっと前にアドベントカレンダーでも書いた Detection Engineering 、そしてそれにともなった Policy as Code の実践と浸透をやっていきたいというのが大きな目標です。長い目で見るとこのトピックは学生時代から追っていた自分にとって生涯のテーマみたいなところがあります。時代の流れとともにやるべきことや技術的な背景は大きく変わってきましたが、それでも根っこの部分である「セキュリティの分野でエンジニアリングをやっていく」というのは共通していると思います。
今回は自力で頑張るだけでなく、社内のメンバーの知見なども借りながら基盤を構築していくことになりそうです。クラウド環境の機能を使い倒していくだけでなく、LLMのような技術の活用も視野にいれています。これについてはまだ構想の段階なのですが、うまく成果がでたらまた後日なんらかの形で公開したいと考えています。
プライベート
やや仕事と関連してはいるのですが、最近英語(特にListeningとSpeaking)を使う機会がわりと増えており、それにともなって英語学習のモチベーションがかなり上がっています。物凄い高いかと言われるとそこまでではないのですが、これまで自らの意志として英語勉強したいと思ったことなど正直一度たりともなかったので、それに比べると自分史上最高の学習モチベーションと言えます。具体的にはListeningの精度を上げること、そして仕事などでの会話で言いたいことがスルッと言えるようになる、というあたりを目指してやっていこうと思っています。
ということで
皆様良いお年をお過ごしください。来年も各位どうぞよろしくおねがいします。
2022年 → 2023年
ちょっと気が早いですが、そろそろ2022年も終わりということで今年の出来事を振り返りつつ、2023年への気持ちをしたためてみます。
2022年
💼 仕事
引き続き Ubie でエンジニア業をやらせてもらってます。
プロダクト(主にバックエンド)開発をするようになった
実は最近はプロダクトセキュリティに関する仕事は必要最低限になっており、プロダクトのバックエンド開発が業務の8割以上を占めるようになりました。取り組んでいる内容についてはいずれ詳しくブログなどで紹介したいと思いますが、実際にユーザに触れてもらう部分を開発するというのは個人的に大きな転機でした。特にプロダクトに関するセキュリティをやる上では「プロダクト開発した経験」が活きる場面がいろいろとあり、良い経験をさせてもらっています。
一方でプロダクトセキュリティの取り組みは全体的に今年は希薄になっていて、自分のキャリア的にこれでいいんだっけ?というのはちょっとあります。しかし普通に今の取り組みが楽しすぎるのでまあいいかという気持ちと、あとはセキュリティとプロダクト開発が両方ちょっとできる人という立ち位置も悪くないかなぁという考えでやっていってます。
チームによる取り組みが多くなった
上記のプロダクト開発にともない、「仕事で1つのプロダクトを複数人で継続的に開発する」というのをやっているのですが、これは実は自分にとって初の経験です。知識として複数人での開発におけるお作法などはある程度知っていたつもりですが、やはり実際にやってみると気づきが多いです。また、明らかに自分一人では難しいスループットが出せるようになり、チームの力というのを実感しています。やはり一人の筋肉でできることには限界がある。
さらに社内のいろんなチームと密にコミュニケーションをとることも多くなりました。こういったムーブはもともとあんまり得意な方ではなかったんですが、今の職場は風通しの良さや透明性、カルチャーの浸透がされており、圧倒的に仕事しやすいと感じています。
🌴 趣味
OSS
今年も休みの日は主にコードを書いて過ごしていたのでいろいろなソフトウェアを作ってきたが、代表作は以下の2つと言って良さそうです。どちらも自分自身で日常的に使っています。やはり自分が欲しい・使いたいと思ったものを実装するのが一番コスパが良いですね。
ゲーム
今まではずっとFGOメインだったんですが、すべての所有キャラをレベルMaxまで育成しつつ、推しサーヴァントを完全体にできたのでややモチベーションが下がり気味でした。しかし待望のメインシナリオである第2部7章が先日開放されて、「FGO最高!FGO最高!」となってます(手のひらクルックル)
一方で春頃に触ってみた原神にかなりハマってます。サービススタート当初は「ゼルダBotWの模造品」のように揶揄されており、自分もプレイしてみた最初の感触はその通りと感じましたが進めてみると全然違いました。平日は終業後にサイクリングマシンで運動しながらデイリークエストや素材集めをしており、ゲームするほどに健康になって便利。原神の方はまだまだキャラ育成とかの余地があるので当分は楽しくプレイできそうです。

2023年
仕事については今携わっているプロダクト開発で取り組むべき課題が見えており、しばらくは開発業に専念しそうです。先日こちらの記事でもちょっと紹介してもらったんですが、社内でGoを推進していく機運があり、そのあたりの音頭取りについても積極的に取り組んでいきたいと考えています。先にも書いたとおり、もともとプロダクトやインフラのセキュリティを中心にやっていたのですが、キャリアの冗長性という観点でもプロダクト開発および運用をちゃんとできるようになるまで経験値が積めると良いなと考えてます。
プライベートではもうちょっと運動量を増やしていくのが目標です。コロナ禍に入ってから逆に運動する時間ができコロナ禍以前とくらべて10kg弱痩せたんですが、このタイミングを逃さずさらに減量したり体作りをしていけるといいかなと考えています。具体的には筋トレをもうちょっと真面目に頑張ろうと思います。体は資本。
ということで皆様良いお年を。来年も各位どうぞよろしくおねがいします。
2021年 → 2022年
大晦日ということで2021年のちょっとした振り返りと、2022年のゆるやかな展望のようなものをしたためておきます。
仕事
2021年
今年の前半はクックパッドにてセキュリティ関連の仕事をやっていました。強く印象に残っている仕事がオフィスの移転とISMSの継続審査でした。継続審査はオフィスの移転などに伴って対応が後手後手になり、結構苦しみながら準備をすることになりましたが、なんとか完遂できました。関係者各位、ありがとうございました。
そして7月末をもってクックパッドを退職し、ヘルステックのスタートアップであるUbieへ転職しました。ちゃんと働き始めたのは9月からなのでまだ4ヶ月程度なのですが、日々の密度が高すぎてもう1年位働いているような気がしています。ヤバい。
仕事内容は引き続きセキュリティ関連なのですが、Ubieは社内のリスク対応を専門にとりくむコーポレートセキュリティのメンバーがおり、自分はプロダクト関連のセキュリティに集中して様々な施策をしています。今取り組んでいるのは以下のようなトピックです。
- インシデント対応体制の構築
- プロダクトの脆弱性診断
- 3rd partyパッケージの脆弱性管理
- OPAによるポリシーコード化の取り組み
プロダクトセキュリティは自分以外にも(専任ではないいのですが)エンジニアがおり、スクラム形式でタスクを回しています。複数のメンバーで同じ領域に集中して取り組むのはなかなか楽しく、いろいろチャレンジングな取り組みもできています。
2022年
今年やってきた取り組みも一定形になってきたかなと思う一方で、成熟度はまだまだかなと思っています。特にポリシーのコード化は社内に広く展開し、活用していきたいと考えています。。プロダクトセキュリティ関連だけでなく、コーポレートセキュリティに関するポリシーもここに乗っけていきたいと目論んでおり、OPAというかRegoの布教を進めている日々です。
また新しいトピックとして「攻めのセキュリティ」をやっていきたいと考えています。ここでいう「攻め」は「その取り組みによって安全性だけでなく利便性や事業速度の向上にもつながるもの」です。例えば異なるプロダクトで共通するようなセキュリティの機能を事業チームとは別に開発・運用できるようにしておくことで、事業チームがサービスの本質的な機能に集中することができるようになります*1。今まで外向けに使われるプロダクトでの開発経験は豊富ではないため身が引き締まる思いではありますが、チャレンジしていきたいなという機運です。
個人活動
OSS
たまに自分が困ったりしたときには他所のリポジトリにPR投げたりしますが、基本的には自分の作りたいものを作りたいように作る、というスタンスでやってます。今年はGo言語を中心にしたユーティリティをいろいろやっていました。
- goerr: pkg.go.dev/errors のようにスタックトレースをつけつつ、文脈を表す変数を引き回せるエラー関数
- golambda: AWS LambdaでGoをいい感じにするやつ。PowertoolsのGo版のつもり
- zlog: 秘匿値をいろんな方法で隠せるGoのロガー
- zenv: 環境変数を読み込んだりMac Keychainに隠して管理したりするツール。これはGo関係ない
あとデカ目のやつとしてはOctovyというTrivyをベースにした脆弱性管理のツールを作ったというか、作っています。これはもともと前職向けに作っていたやつなんですが、環境がAWS → GCPになったおかげでほぼフルスクラッチで書き換えることになりました*2。
登壇とかブログとか
転職が挟まった&ご時世的な状況もあり、ほとんど登壇はなかったです。唯一、自社でホストしたTech Talkイベント(発表資料)で脆弱性管理の話をさせてもらいました。
ブログは自分の作ったものを説明したりするときにふらっと書く程度だったんですが、12月はOPA/Regoの一人アドベントカレンダーというのをやりました。我ながら頭がおかしいですね。
前々から準備していればよかったんですが、これやるか決めたのがそもそも11月中旬で、しかもその時点では「OPAってたしかk8sの設定チェックするツールだっけ?」みたいな状態でスタートしたので、25日分の記事を書くのはなかなかにハードモードでした。もう二度とやらんぞ。
私生活
転職という大きな節目はあったものの、基本的には前職・現職ともにほとんど在宅勤務のスタイルだったので、基本自宅に引きこもりという生活スタイルでした。たまたまこのご時世に突入する直前の2019年末にマンションを購入していたのですが、ちょっと広めの1LDKを選択していたのが僥倖でした。スペースの余裕は心の余裕。
自宅環境の大きな変化はスタンディングデスクを購入したことで、最近おそらく8割以上の仕事時間は立ちながら作業しています。今も立ちながらこの記事を書いています。これで足腰が鍛えられているのかどうかよくわかりませんが、最初の頃は2、3時間くらいで疲れていたのが5、6時間立ちっぱなしでも大して疲れなくなったので一定効果がありそうです。

まとめ
というわけで2021年も各位大変お世話になりました。2022年も引き続きどうぞよろしくおねがいします。
*1:このあたりの話に興味がある方はぜひこちらをご参照ください https://mztn.hatenablog.com/entry/2021/11/04/092940
*2:Lambda+DynamoDBだったのをCloud Run+PostgreSQLにしたので、ほとんど異世界転生だった
Ubieで一緒にセキュリティをエンジニアリングしていってくれる方を募集中です
TL; DR
- セキュリティエンジニア(プロダクトおよびコーポレート)絶賛募集中です
- セキュリティだけを専門でやられていた方だけでなく、サービス開発が中心だったけどセキュリティも少しやっていたみたいな方も大歓迎です
ヘルステックのスタートアップであるUbieで働き始めておよそ2ヶ月ほどたちました。入社する前からなんとなくは知っていましたが、メンバーの熱量の高さや能力の高さに圧倒され続けています。事業についても患者さん向けのユビ―AI受診相談や医師向けのユビーAI問診が中心ではあるものの、その枠に留まらない新しいチャレンジを多角的に取り組んでおり、とても刺激的な日々を過ごしています。自分はセキュリティエンジニアとして入社させてもらい、まだ大きな進捗はないもののUbieで提供するプロダクトやそのプラットフォームのセキュリティを向上させる取り組みをさせてもらっています。
転職した理由として、事業ドメインや成長フェーズの異なる会社に移り、自分の技術や知識、そして考え方が通用するかというのを試したいというものがありました。入社前からいろいろと社内の話はいくらか聞いていましたが、実際に働いてみることで徐々に自分の中で取り組むべき具体的な課題がはっきりしてくるようになりました。同時に、1つ1つがとても重い話で一緒に取り組んでくれる仲間がもっと必要であるということも分かってきました。
そこで、Ubieがこれから取り組みたい課題について言語化してみつつ、どういった方を探しているかについてまとめてみました。興味を持っていただいた方がいたら、ぜひお話させてもらえると嬉しいです。
Ubieにおけるセキュリティのチャレンジ
DevSecOps
バズワードのため定義がはっきりしないDevSecOpsですが、自分の中では以下のように定義しています。
- プロダクト開発の各段階で必要なセキュリティの要件を満たしていける
- プロダクト開発で継続的に脆弱性が入り込んでいないかのチェックをする
どのサービス事業会社もそうだとは思いますが、Ubieでは特にプロダクトの機能拡張や新しいプロダクトの開発がものすごいスピードで進んでいます。「今度こういう機能を実装する予定なんですよ」 → 「もうできました」みたいな爆速事案をしばしば目撃します。それゆえにプロダクトの変化が激しく、セキュリティ上問題になるような仕組みになっていないか、扱うデータが適切か、脆弱性などが入り込んでいないかなどを常に気にし続けなければなりません。セキュリティを専門に理解している人が張り付くという方法もあるかもしれませんが、スケールしないというのが難点です。
これを解決するアプローチとして仕組み化と自動化を積極的にやっていきたいと考えています。この問題は単にCIにセキュリティチェックを組み込めばいいというわけではなく、どうすれば開発するメンバーの負荷にならないようにセキュリティを向上させられるかを模索していかなければなりません。そのためどちらかといえばプロダクト開発の経験があり、かつセキュリティに対して興味がある、というような方と一緒にチャレンジできると面白そうだなと考えています。
全社共通・横断のプロダクト向けセキュリティ機能の実装
前述したとおり、UbieではユビーAI受診相談およびユビーAI問診という2つのプロダクトを主軸としていますが、それらの拡張だけでなく新しいプロダクトの開発も積極的に取り組んでいます。これら全てのプロダクトは医療に関係するものであり、各々でセキュリティの機能(認証認可、プライバシー保護、監査、リスク分析など)が必要があります。
プロダクトが少ないうちは個別に実装するほうが柔軟に動けるなどのメリットがありますが、プロダクトが多くなってくると実装水準のばらつきや全社的なコントロール、状況把握が難しくなるという課題があります。そこでプロダクトが成長・拡大しようとしているこのタイミングで、全社共通のセキュリティ関連機能を実装したいと考えています。これによって、各プロダクトが必要なセキュリティの水準を満たしつつ、サービス開発者が開発のスピードを上げられるという恩恵も得られるようになると期待されます。
具体的な事例として、認証認可基盤の構築があります。開発するプロダクトが増えることで、認証認可の仕組みをどのように整えていくかという問題と向き合わなければいけません。現代の認証認可の仕組みは単純なID・パスワードの組み合わせを保持すればいいというだけでなく、多要素認証や様々なデバイスからの利用、そしてサービス間の連携を考える必要があります。Ubieが新しいプロダクトや機能を展開していくとなるとその間の認可をどのように制御すればいいかも考える必要があります。
この機能もプロダクトごとに開発すると実装水準にばらつきが出てしまう他、将来的に会社横断で統合するとなると時間が立つほど移行の苦しみが大きくなってきます。今まさにプロダクトが広がっていこうとしている中でこのような仕組みをゼロから設計・実装できるというのは絶妙なチャンスだと考えていますが、自分はこういった仕組みを知識として知っているだけで、実際に大規模な基盤を実装・運用した経験がありません。そういった知識・経験・実装力をもった方にぜひ力を貸していただきたいと考えています。
社内の統合的なセキュリティの向上
Ubieは現在急速にメンバーを増やしつつあり、そのため社内システムや働く環境のセキュリティについても急速に整えていく必要があります。創業したばかりのベンチャーだとよくあることかもしれませんが、Ubieは事業を加速させるために社内のメンバーが自ら各種クラウドサービスを積極的に導入・活用するという文化が根づいています。現状、管理体制として2020年にはISMSを取得し、3省2ガイドラインの準拠を進めるなど、社内体制やシステム側の安全管理を急速に整えてきています。しかし今後世界市場に拡大するためにも、今ある文化を活かしつつ、安全かつスムーズに各種サービスが使えるようなサービス統制や環境整備をさらに進化させる必要があります。
また、各社内システムなどで一定のセキュリティを保つような設定をしているものの、統合した守りの体制を構築していく必要があります。例えば各システムの状況をセキュリティ観点で監視・調査したり、アラートの調査や対応をしたり、セキュリティ関連のエンドポイント製品の導入や運用をしたり…というようなものがあります。これらをバラバラに使うのではなく、それぞれを連携させて機能できるようなグランドデザインをしながら実装・運用をしていく、という試みが必要です。
このような体制を整えていくにあたり、人手を増やすことでスケールさせることも時には必要ですが、近代的なシステムやツールの力を使い、人だけに依存しないような構造を考えていく、というところにエンジニアリングとしてのチャレンジがあるのではないかと思います。そういった取り組みに興味がある人と是非一緒に取り組んでいきたいと考えています。
どういった方に来てもらいたいか
「セキュリティエンジニア」という募集をすると「ずっと情報セキュリティを専門にやってきた方のみを対象にしている」と思われがちですが決してそんなことはありません。特にセキュリティベンダー以外のユーザ向け企業などにおいて、セキュリティの分野というのは業務や開発といった営みに強く関係するものであり、時としてそちらについての知見が必要とされる場合もあります。
もちろん一定のセキュリティに関する知識やエンジニアリングに関する技量は必要となりますが、セキュリティ以外のことについてもいろいろ取り組まれていたり、メインは開発だけど実態としてプロダクトのセキュリティ関連のケアをしてきた、というような人にもぜひ興味を持っていただけると嬉しいです。
meetyのカジュアル面談募集のリンクも以下にありますので、興味を持っていただけた方はぜひお声がけください。お待ちしています!
その他関連リンク
2021年8月の夏休み
先日ブログに書いたとおり7月末を最終出社として退職し、8月は有給消化期間にした。学生時代以来の長期夏休みを獲得したし、8月上旬にはfully vaccinatedになっていたのでうまくいけば8月下旬にふらっと旅行するぐらい大丈夫なんじゃないかな、とかちょっと期待していたらデルタ株によってご覧の有様である。
そんなわけで折角の機会にも関わらず1ヶ月間は自宅の半径2kmから出ることなく過ごす羽目になってしまい、何もなさすぎて自分でも何をしていたのか忘れてしまいそうなのでブログをしたためておく。
読書
転職先の推薦図書をいくつか読んだ。
Measure What Matters
OKR (Objectives and Key Results) の仕組みや効果についてひたすら書かれている本。OKRというものに触れたのが初めてだったので最初はよくある目標設定とどう違うのかというのがピンときていなかった。今回、自分が読んでなるほどなと思った点は以下の3つだった。
- 「やるべき重要な取り組み」の優先順位は組織でも個人でもすぐにブレる。なので方向性を揃えたり修正したりするためにOKRが使える。
- 全社的にOKRというシンプルなプロトコルを使うことで目標管理のコミュニケーションがやりやすくなる。特に全社で定めたOKRが下位のOKRとつながることで、会社としての取り組みに整合性がうまれたりメンバー間の協力がしやすくなる。
- OKRは「組織にとって価値あることに集中」するための仕組みで、成果をトラックする&必要に応じて柔軟に変更するという運用をやって初めて効果が発揮される。
- 個人の成績と紐付けてはいけない。なぜなら「組織にとって価値あること」ではなく「OKRを達成すること」が重視されるようになり、間違っていたり環境変化によって効果的ではなくなってしまったOKRでもそれを達成させようとする力学が働くから
How Google Works
おなじみのGoogleが内部でどういう思想でどういう運用をしているかについて書かれた本。全体的に話がちょっと古い(2000年代ぐらいの話が中心)なのと、結果論なのではと思う話が多いきらいはあるものの、 "Googleっぽさ" をいくらか理解できたかなと思う。この本で書かれているような内容も現在においてはすでにいろいろな会社・組織に取り入れられるようになったなと感じており、読んだ率直な感想としてすごい斬新だとは思わなかった。ただ、もともとの根幹の話に触れておくのは大切だし、良い機会だったと思う。
1兆ドルコーチ
シリコンバレーのbig tech企業を中心にコーチングの才を発揮していたビル・キャンベル氏の逸話集。氏の類まれな能力や人格による話なので全てをそのまま実践するのは難しく、体系だてた話でもないのでスッと理解するのも難しい。とはいえ自分に足りない人間力的なところで学ぶべきてきなところや、これからチャレンジしていくべきポイントという意味では学びがあったかなと思う。
開発
個人開発で手を付けたもの。
AlertChain
Security Orchestration, Automation and Response (SOAR) の小さい実装。前職にいたときはAWSのフルサーバレスアーキテクチャでDeepAlertというSOARを実装していたが、次の職場ではGCPなので可搬性ゼロで無事終了していた。ということでコンテナベースで動くものを作ろう思い立ったのだが、この機に最初から設計し直すかとなってフルスクラッチしているのがこのAlertChain。
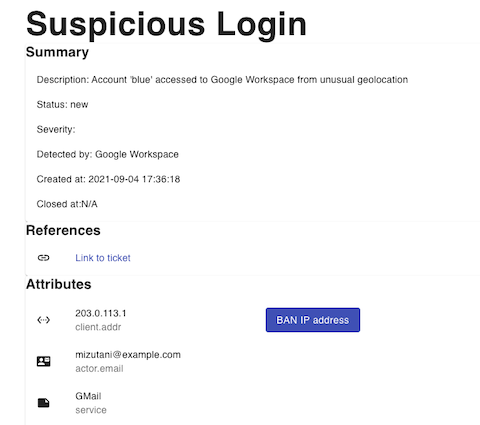
基本的にはセキュリティアラートを受け取って、1) アラートに対して事前に定めたワークフローを自動的に実行する、2) 追加のワークフローを管理画面から実行できる、という2つだけの機能が主軸。事前に定めたワークフローでは、アラートにでてきたIPアドレスをOSINTしたり、条件に従ってリスク判定したり、どこかに通知したりというようなユースケースを想定している。一方、追加のワークフローというのはもうちょっとアグレッシブ&人間の判断を挟んだほうが良さそうなもので、例えばinstanceをtermianteしたり、ユーザ権限をsuspendさせたり、みたいなのを想定している。下図は対象IPアドレスをBANさせるという追加ワークフローの例。
前作との違いを少しふれると、以下の3点。
- 前作は各ワークフローがばらばらになっていてテストがしにくかったのを悔い改め、AlertChainでは全ワークフローを一気通貫でテストできるようにした
- 1プロセスだけで動くようにして運用やデバッグをやりやすくした
- AlertChain自体がちゃんとアラートの情報を保持するようにし、管理画面から確認できるようにした
正直、まだ荒削りというレベルにすら達していないが次の職場に導入していきたいと画策していて、運用していく中でブラッシュアップしていきたいと考えている。もうちょっと整ってきたタイミングで解説記事などを改めて書きたい。
zenv
開発などで手元のPCで環境変数を扱う時、envchainを活用しているが、秘匿値以外の環境変数もいい感じに扱えるツールがあると便利だなといろいろ思案した結果、結局envchain + dotenvのようなツールができたというのがこれ。なので既存ツールを組み合わせでどうとでもなる範疇の実装ではあり、人様に強く進めたいというほどのものではない。ただ、 .env ファイルに通常の環境変数だけでなく秘匿値の指定(秘匿値は実際にはkeychain内に保存してある)をしたり、読み込んだ環境変数を元にコマンドライン引数を書き換えたりができるようになっているので、個人的には便利。
利用イメージとしてはこんな感じ
$ zenv secret write @aws-account AWS_SECRET_ACCESS_KEY Value: # コピペなどで入力 $ zenv list @aws-account AWS_SECRET_ACCESS_KEY=**************************************** (hidden) # 読み込んだ環境変数を表示。秘匿値は伏せ字にする $ zenv @aws-account aws s3 ls (snip) # S3のリスト表示 $ echo "AWS_REGION=ap-northeast-1" > .env $ zenv list @aws-account AWS_SECRET_ACCESS_KEY=**************************************** (hidden) AWS_REGION=ap-northeast-1 # .envファイルからも読み込み
生活
ダイエット
特に意気込んでやっていたわけではないんだけど成果はでていたので、したためておく。運動+なんちゃって糖質制限的なやつを6月末からやっていて、だいたい3kgぐらい減量した。
運動は実は去年からずっとエアロバイク30分程度というのを中心にほぼ毎日やっていたのだが、いまいち減量するにはいたならかった。そこでなんとなく食事量(特に糖質)を減らしてみたところ、徐々に体重が落ち始めたので惰性で続けてみて今に至る。
食事はbase breadとnoshを活用しており、自分ではオートミールをベースにした炒飯とかカレーとかを調理したりしている。あと鶏むね肉やローストビーフをバッチで継続的に低温調理している。糖質はだいたい1日あたり平均して120gぐらいなはず。あとFitbitに食事管理機能があるのだが、定型の食事(それこそbase breadとかnosh)を摂る場合は計測しやすく便利。記入漏れとかもあるからあまり正確ではないが、概ね1日あたり500〜600kcalほどは消費カロリー量が上回っているらしい。
豚肉キャベツ卵納豆とオートミールでチャーをハンしたやつ pic.twitter.com/GC6gE8LRdI
— mizutani (@m_mizutani) 2021年8月8日
最近はまっているやつ
— mizutani (@m_mizutani) 2021年9月4日
・鶏胸肉を60度4時間くらいでアノーバする
・薄切りにする&冷やしてる場合はレンチン
・刻んだネギを盛る
・ごま油ちょい+塩ちょい+白だしとお湯を1:1ぐらいを混ぜてぶっかける
普通に美味くてスルッと食べれるし小腹が空いた時に便利 pic.twitter.com/hIMGtVzOZk
長らく米を食べていないので「たまにはがっつりカツ丼とか食べたい!」と思うことはままあるものの、今のところそこまで辛い気持ちにはなっていないので、無理なく継続してシュッとしていきたい。
ゲーム
MONSTER HUNTER RISE
エアロバイクのお供。毎日30分くらい野良で狩りに行っている。エアロバイクをやっていることを程よく忘れられるくらいの集中力が必要。他のゲームも試してみたが、あんまり没頭できないゲームだと「漕いでいて辛い」という気持ちが続いてしまうのだが、モンハンはいい感じに没頭できる。あと1サイクルが10〜15分くらいなので、2〜3回やっていると運動時間が終わるというのも良い。トータルのプレイ時間はそんなに長くないのでHR200ちょいぐらい。
ただ最近さすがにちょっと飽きは感じ始めているので、代替になりそうなゲーム無いかなとは思い始めている。
Factorio
無人の星に不時着してしまったエンジニアが資源を集めて建物や工場を作り、武装や物流システムを発展させていくゲーム。一応、生産物の一つである「ロケット」を作るとクリアとはされているのだが、マップが無限に広がっておりクリア後も工場を発展させることができる。
このゲーム、去年末くらいにめちゃくちゃハマって300時間くらいプレイし、自分なりの物流システムの最適解に至るまでやりこんだ。ところが、あまりに工場をでかくしすぎて処理負荷が大きくなりゲームがまともに動かなくなってしまったので、それ以降あまりプレイしなくなっていた。で、特に何かあったわけではないんだけど、ふともう一度ゼロから始めるかとなり、異世界転生よろしく2周目の知識を活かして、丁寧かつゆるゆるとしたプレイをしている。

月姫
もう永遠に発売されないんじゃないかと思っていたけど、本当に発売されたよ! ありがとうTYPE-MOON!!
とりあえずの感想として結構演出も凝っているし(「魔法使いの夜」に近い)フルボイスなのでオートモードでプレイしていると実質アニメを見ているのに近く非常に快適。そのため自分の進行はとても遅くまだ序盤も序盤。ただ原作未プレイ勢ではあるものの、結末とか世界設定とかはだいたい知っているのでゆるゆる一月ぐらいかけて楽しんでいくつもり。
転職します(Cookpad → Ubie)

2021年7月30日を最終出社日として現職のCookpadを退職し、9月からUbieという医療系のスタートアップに入社します。
Cookpadでのこれまで
2017年11月に入社したので、在籍期間は4年弱でした。この間、組織変更に伴う部署異動はありましたが、ずっと情報セキュリティに関わる業務をやってきました。
システムのセキュリティ対策
主な業務は「インフラや社内システム、開発サービスに対するセキュリティの機能をエンジニアリングによって向上させること」でした。 製品やサービスをそのまま導入することもありますが、自分たちの必要に応じて既存ツールを拡張したり、全く新しいシステムを自作することもありました。 例えば以下が代表的なやつです。
セキュリティに関する社内の問題を見つけ出してエンジニアリングによってそれを解決していく、という仕事内容は自分の志向とマッチしており仕事はとても楽しかったです。 さらに仕事で取り組んだ結果を発表する機会も各所から多くいただき、これについてもありがたかったです。 USに飛んで英語で撮影するぞという話を突然もらって、七転八倒しながら達成したのも良い思い出です。
ただ調子に乗っていろいろやりすぎてしまった感があり、退職に伴って大量のシステムを引き継ぐことになってしまった点については少し申し訳ないなと感じている次第です。
社内リスク対応
いわゆる社内の情報セキュリティ委員会というやつもやっており、社内で新たに起きる情報セキュリティのリスクをコントロールするということもやっていました。 自分もこの業務に携わるまであまり意識したことがなかったんですが、会社の活動というのは目まぐるしく変化し、それに伴って様々なリスクが発生します。 そういったリスクに対応するため、どんな情報システムを使ったらいいのか、どのように使ったらいいのか、どんなデータを扱っていいのか、という相談をうけたり判断をしたりということもやっていました。
これは単純に社内ルールに準拠するだけでなく、法律や規制などについても配慮し、とりあつかう情報の重要度などから実際のリスクを考え、現実的な落とし所を考える必要があり、最初のうちはかなりハードな業務でした。 自分もそもそも法律などについては素人だったり、(セキュリティの人にありがちですが)過度に安全側に倒して現実的でない方法になってしまうなど四苦八苦していました。 しかし同僚の助けも借りつつ最終的にはある程度の部分をこなせるようになった気がしており、自分としてはなかなか良い経験値になったのではと思います。
その他会社生活全般
組織のカルチャーや雰囲気も自分にとってはかなりマッチしていたと思います。 前職が大手SI企業だったこともあり、そのギャップの衝撃から入社直後にわりとはしゃいでいる記事を書いたりしていました。 さすがに今はもうこの記事のテンションはありませんが、ここで良かったと感じたことは特に変わっていません。
今回の転職直前にオフィスが恵比寿からみなとみらいへ移転するという一大イベントがありましたが、これについても今回の転職とはあまり関係ありません。 個人的にみなとみらいはいろいろ思い出深い土地で気持ちがあったし、WeWorkの無限にビールが飲めるサービスとか楽しみにしていたのですが、情勢によって結局ほとんど恩恵に預かれませんでした。悲しい。
めちゃくちゃいい天気@みなとみらい pic.twitter.com/UmRlo4tWT1
— mizutani (@m_mizutani) 2021年7月27日
転職のきっかけ
ということで現職に対して特に厳しいことがあったというわけではないのですが、自分の能力の幅を広げるという観点でこの度転職をすることにしました。
セキュリティエンジニアのキャリアパスというのもいろいろあると思うのですが、自分は「システムのセキュリティ対策」というのがやはり最も興味の強い範囲で、 これを継続していった場合にどのようにキャリアを重ねていけばいいのかという点についてはこれまでずっと模索してきました。 社内リスク対応の方はパスとして例えばCISOになるというような話があったりすると思いますが、 どちらかというと現場でエンジニアリングしていたいので、役職を上げるのとはまた違うかなと考えています。
というようなことを長らくもやもやと考えていたのですが、あるきっかけで「違う事業ドメインにチャレンジしてみることで幅を広げるのがいいのでは」と思いつきました。
同じWeb系であっても他社のセキュリティ担当の方と話させてもらうと、やはり会社の事業ごとにリスクであったり守るべき資産の捉え方というのが大きく違うな、というのは以前から感じていました。 そのため現職でうまくいっている事例を話しても「うちとは(環境や背景が)違いますね」という反応になることがあり、自分のやっていることが他の会社や事業ドメインでどのくらい通用するのか?というのが未知なままでした。 そこは確かにやってみないとわからないので「だったら環境を変えてチャレンジすることでより多くの場所で通用することを増やしていこう」と考えるようになりました。
Ubieでのこれから
というわけで冒頭で書いたとおり、Ubieという医療系のスタートアップに転職することにしました。現状では医療機関向け、および患者さん向けのサポートをして患者さんを適切な医療へつないでいく、といったサービスを提供しています。(私もまだ事業の細かいところを知っているわけではないので、詳しくはこちらの資料を見ていただくか、あるいは興味のある方はぜひお声がけください)
Ubieに決めた理由
実は今回の転職では他の会社の選考は受けておらずUbie一本だった*1ため、他社との比較はしていません。普通に考えて転職するときは複数社を受けてオファーを並べて検討するものと思うのですが、1社目で転職しようと考えた決定的な理由は以下の2つでした。
- 事業ドメインが今までと大きく違う
- セキュリティをエンジニアリングしていくことへの理解
1については転職のきっかけの話の通り、事業ドメインがなるべく違うところが望ましいというのがありました。 特にセキュリティに対しての厳しさでいうと自分の中では医療と金融が最も難しい分野であり、その片方である医療の分野というのは自分の思惑にとてもマッチしていました。 また、事業についても「今あるアナログなビジネスをちゃんとデジタル化していく」という分野は個人的にとても面白く、熱い領域であると考えています。 (流行り言葉を使うといわゆる "DX" になるんだと思います) Ubieの事業が医療機関に関わってくることで自分たちのサービスだけでなく、医療機関でのセキュリティというのも同時に携わっていく必要があり、 それについてもチャレンジングで興味深いと考えています。
自分の中でさらに決定打になったのは2の「セキュリティをエンジニアリングしてくことへの理解」が大きかったです。 これはCookpadへ入社する際の転職活動で感じたことでもあるのですが、 いわゆるセキュリティの問題に対して製品やサービスの導入するだけでなく、 ちゃんと自分たちでエンジニアリングをして問題を解決しようというマインドを持った組織というのは日本だとまだかなり少ない印象です*2。 Ubieのメンバーとカジュアル面談をした際に彼らもその課題感をもっており、しかしまだそこにアプローチするメンバーがいないという話を聞いたときに、 ここで働いてみたいなとう気持ちが強くなったことを覚えています。
この他にもマネジメント的な上下関係がない組織構造(ホラクラシー)や評価のない制度、会社の雰囲気など惹かれた部分はいろいろあります。ただまだ直接働いたわけではなく「良さそう」という印象でしかないので、詳しくはいずれ別の機会にという感じです。
やっていきたいこと
というわけでUbieへの転職後も引き続きセキュリティエンジニアをやっていく予定です。
今回は医療という領域になるため、リスクに対する考え方や対応がよりシビアになっていくのではないかと考えています。 利用してもらう人のために十分な安全性を担保していかなければならないのですが、じゃあどこまでやったら「十分か」ということを常に見極めていく必要があります。 そうしたことを突き詰めていく課程で、最適なセキュリティとはなんなのか?、そもそも最適というものがあるのか? ということを考えていきたいと思っています。
また自分の密かな目標として、サービス運用をソフトウェアエンジニアリングの方法でアプローチするSRE(Site Reliability Engineering)にあやかり、Security Reliability Engineering*3の方法論を探求していきたい、というものがあります。 Site Reliability EngineeringはもともとGoogle社内で運用にまつわる作業や問題をソフトウェア開発の考え方・発想・手法で解決する方法論を体系化して世に出したのが発端という認識です*4。 この着想はセキュリティに関する運用にも適用でき、ソフトウェアエンジニアリングの応用で解決できる問題というのは多くあるのではないかと自分は考えています。 ただSREとは領域や前提がいろいろ違うためそのまま持ってくることはできず、セキュリティ分野ならどうかということを改めて検討しなければなりません。
自分が新しい領域でチャレンジすることでSecurityのReliability Engineeringの方法論を体系化していく足がかりになればと考えており、引き続きやっていきたいと思います。
ということで
各位、引き続きどうぞよろしくお願いいたします。
シン・エヴァンゲリオン感想(ネタバレあり)
3月8日の11:00〜の回でシン・エヴァンゲリオンを観劇してきました。基本的ただの雑感のなぐり書きですが、旧劇の「閉塞の拡大」をBGMに聴きながら今のお気持ちをしたためておきます。思春期から拗らせた者の末路なので、その前提でご笑覧ください。
ネタバレしかないので、ご注意ください
全体通して
「まとまった…な…?」みたいな感じ。
アニメーションとしてはめちゃくちゃ動くしすごかったけど、エンターテイメントとしては序や破の方が好きだし、旧劇劇場版のようにバチバチに尖ったところもなかったなという感じ。とはいえこれまでの物語を締めようとしているというのがしっかり見えて「あーこれで終わりなんだな」というのを実感させられた。四半世紀に渡る因縁に対してスパッと決着ついたのかと言われるとちょっとわからないけど、とりあえずこの作品を世に出してくれてありがとうという気持ちです。
その他雑感
序盤〜ヴンダー出撃
- 小出しにされるコンテンツ見るの嫌い派なので先行映像は一切観なかった、ので冒頭の戦闘シーンは登場する敵含めてちょっと意表をつかれて良かった
- 村の生活で人間性を獲得していく綾波に対し、どんどん人間性を失っていくシンジがちょっと哀れ
- シンジ、旧劇ではわりと「そんなことでうじうじしているんじゃない」みたいな感じがあったけど今回の件はまあそりゃ落ち込むよね…、という納得がめちゃくちゃあった
- とはいえ旧劇劇場版みたいに最後までこのテンションだったらどうするんや…と思っていたけど、ちゃんと復活してくれてよかった
- アスカにけちょんけちょんに言われてたけど、自分で世界滅ぼしかけて目前で友人殺されてという状況からちゃんと立ち直るの、むしろ強靭メンタルすぎでは?
- アスカとケンスケがいい仲になっていたのは最初「まじで!?」ってなったけど、個人的にはなんかわりとすんなり受け止められた。一方、一緒に見に行った友人は許せていなそうであった。古のオタクは難しいのだ
- プラグスーツの電源がなくなる描写、そのまま爆発でもするんじゃないかとヒヤヒヤした
異空間での戦闘〜シンジ覚醒
- 誘導弾、「完全に無人在来線爆弾じゃねーか」と思わずツッコミ
- 「ヤマト作戦」とかその他あれこれで、ああ庵野監督は本当に宇宙戦艦ヤマト好きなんだなぁと実感
- ミサトさんとシンジのコミュニケーションが落ち着いたものでなんか良かった
マイナス宇宙〜終劇
- 親子プロレス(初号機vs13号機)は、仮想世界での戦いという演出はすごいわかるんだけど、なんかギャグっぽく感じてしまいうーむという印象
- 「特撮っぽい描写」を演出するために色んな要素をチープにしていたと思うんだけど、あそここそ全力全開最高作画をやってほしかった
- 異空間とかスケールのデカさからなんかグレンラガンを想起した
- 旧劇のお家芸、精神世界描写もでてきたり、旧劇のラストに通じるアスカのシーンも会ったりして「あー、ほんとうに過去の因縁を終わらせようとしてくれたんだな」というのを感じた
- しかしこれ新劇だけ観てた人にはわりと「?」になったりするんじゃないかな
- 本当は旧劇もこうありたかったということなんじゃないかなー?
- 旧劇だとゲンドウについてあまり語られなかったけど、今回の深堀りで普通にまるでダメなオヤジだったことがわかりちょっとニッコリした
- われながらちょろいけど髪下ろしたミサトさんいいよね、、となりました
- 最後のシンジの相手がマリだったのは、嫌ではないんだけど個人的には納得いかず
- そもそも君たち本作でやっとちゃんとした面識持ったというぐらいの仲じゃん…。
- 個人的にはあのポジションはレイだった。アスカはケンスケとよろしくやっているのでヨシ
- これはなんか過去作に気づいてない伏線とかあるのかもしれないので考察班を待ちます
- 最後が実写だったのは、監督からの「現実に帰ってこい」的なメッセージを感じましたね
- 旧劇時代に比べ、監督が結婚して拗れが解消したという説はわりと信憑性があると思う