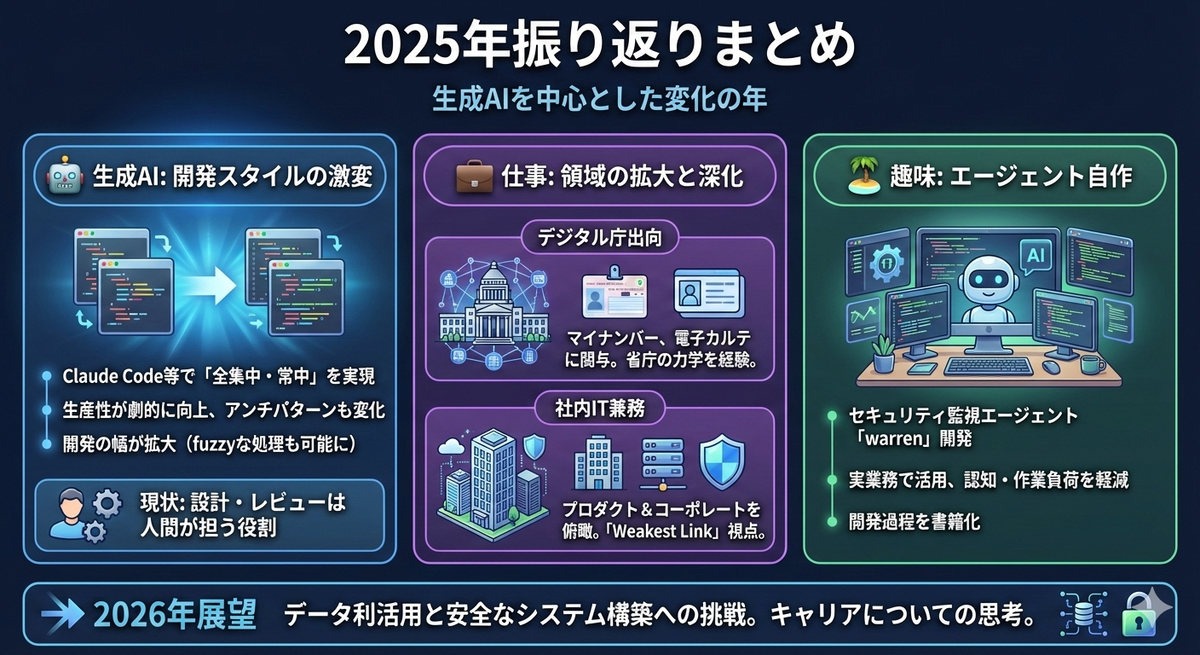
毎年恒例、近況報告を兼ねて振り返りをしておこうと思う。
2025年振り返り
🤖 生成AI
とにかくまず2025年と言えば生成AIの話抜きでは語れないと思う。5月頃にでたsonnet4とClaude Codeの体験が強烈過ぎて、その後の開発はほとんど生成AIベースのツールをフル活用するようになっていった。それまでコードを書くときはそれなりの集中力を必要としていたので、1日あたり全力で書けるのが4時間程度だったと思う。これがClaude Code、Cursorのようなツールを使うことで1日8時間以上やっていてもそこまで疲れなくなった。鬼滅の刃風に言うなら「全集中・常中」を会得したに等しい。しかも指示さえ的確なら自分の数倍の速さで実装できる。ちょっとした隙間時間にも実装を進められるようになった(このブログを書いている裏でも2プロジェクトに対してClaude Codeを走らせている)。また、自分が苦手な言語や領域1でも簡単に実装できるようになったのも大きい。
これによって多くのソフトウェア開発におけるアンチパターンが覆され、考え方も変わってきたと感じる。例えばツールやシステム内製はよほどの余力がなければ極力やるべきではないというのが今までの常識だったと思うが、これが要件・コストに見合うなら検討の余地があるというようになってきた。これは社内の情報活用やセキュリティ、コーポレートの課題を解決しやすくなったことで、喜ばしいと思う。
コーディングエージェントだけでなく生成AIによってソフトウェア開発の幅が大きく広がったことも大きい。いままでは常に決定性の高いロジックを組み立てる必要があり、それが機能実装に大きな制約を与えているものもあった。この制約を取り払い、fuzzyな処理の実装難易度が激減したことで、これまで実現が難しかったいろいろな機能を実現できるようになった。
一方で生成AIが全ての問題を解決しているかというと全くそんなことはない、というのが現状の個人的な所感である。ことソフトウェア開発においてはコーディングの負荷こそ激減したが、設計、レビュー、問題解決についてはまだ人間が多く役割を担っている。ソフトウェアエンジニアの役割が「継続的にソフトウェアの機能を提供・拡張していくこと」だとするなら、まだ生成AIが担えている役割はそこまで多くないと言える。しかし来年以降もしばらく生成AIへの投資と性能向上、さらにエコシステムの発展があるとすると2026年もまたいろいろと変化があるのではないかという期待はある。
💼 仕事
基本的にはこれまでどおりUbieでセキュリティ関連をメインとしているのだが、思い返すとここしばらくは結構変化が大きかった。
デジタル庁
ここまで公には伏せていた話を一つ開示すると、実は去年の8月から今年の7月までデジタル庁に出向2的な形で勤めていた。フルタイムではないがそれなりの割合で業務をしていた。デジタル庁に勤めることになった経緯はちょっとややこしいので、オフラインで聞いてもらった方にはお話しようと思う。
所属していたのはマイナンバーポータルを司るチームで、開発プロジェクトにも参加させてもらった。またサイドワークとして標準型電子カルテのプロジェクトにもかかわらせてもらった。もちろん開発といっても自分ではコードを1mmを書くことはなく、委託事業者に作成してもらった設計や計画書をレビューするというのが主な業務であった。設計などについては思うところがいろいろとあったが、歴史的経緯や他省庁との関係によってままならないことが多いと分かったのも興味深かった。特に省庁内外で物事を決めたり進めたりするための力学というのが、こうやって働くんだなぁというのを目の当たりにできたのは貴重な体験であり学びが多かったと思う。
デジタル庁は民間人材も多く登用しており、私の周りにも多く在籍していた。デジタル庁についてはその所管からエンジニア界隈でいろいろと言及されることも多い。個人的には、関心がある方はぜひ内部で働いてみるという選択をおすすめしたい。ままならないことも当然ある一方、ちゃんと影響力を発揮して政策をエンジニア観点で良いと思える方向へ舵切りしていくことができる職場であると思う。
コーポレートエンジニアリング(社内IT)
これは何度かX(formerly Twitter)でも呟いていたが、デジタル庁の業務を終えてUbieに完全復帰したあと、諸般の事情によってプロダクト側のセキュリティだけでなくコーポレートエンジニアリング、いわゆる社内ITも掛け持ちをすることとなった。もともと現職でもEDRの運用などには携わっていたし、前職でもコーポレートエンジニアリングチームと一緒に仕事をすることはあった。しかし実際に主体的に業務をやってみるとなかなかに難しいことがわかる。今や企業活動のほとんどがデジタル化できるようになったがため、その根底をほぼ全てコーポレートエンジニアリングで支えなければならないのだなというのを再認識させられた。
現状だと自分は主務というより補佐的な立ち位置で入っているだけだが、それでも社内システムの全体アーキテクチャのような広範な話から、個別のSaaSや端末のデバッグみたいな話まで入り乱れており、なかなかに大変である。しかし一方で、セキュリティをやっていくうえではコーポレートもプロダクトも地続きであり、それらを俯瞰してみられる立ち位置になったというのは悪くなかった。「Weakest Link」という言葉があるとおり、セキュリティは「最も弱い箇所がその組織全体のセキュリティ強度を決める」と考えられる。これは単純なサイバーセキュリティ的防御に限らず、社内の統制や権限管理という観点からも全体を見て施策を考えられるというのは大きい。
業務分掌が増えたことはシンプルに大変なのだが、そういった観点から個人的にはかなりポジティブに捉えている。またエンジニアリングによってなにか効率化するみたいなのも大好物なので、そういったチャレンジもしていきたい。
🌴 趣味
今年の趣味の目玉はなんといってもこの生成AIエージェントを自作していたことだった。
セキュリティ監視における生成AIの活用は去年(2024年)の末頃から取り組みはじめ、あーでもないこーでもないと試行錯誤を繰り返していた。最初のうちはルールのチューニングやアラートの整理といったごく一部のワークロードに対してのみ生成AI活用を試みていた。しかしClaude Code、CursorのようなAIコーディングツールに触れていくなかで、「もう全部エージェントにやらせればいいじゃん!」となりそこからずっと作り込みを続けてきた。
現在このwarrenは実業務でも活用されており、自分だけでなくチームメンバーにも活用してもらっている。自分の業務が楽になるようにと言う目的で作ったので自分が良い思いをしているのは当然なのだが、他のメンバーからもなかなか受けが良い。
ちょっと自画自賛をするなら、このエージェントの良さは「セキュリティ監視業務における認知・作業負荷の軽減」なのだが、これがなかなか言葉だけでは伝わらないのがとても残念である。実際に使ってもらえると結構わかってもらえるのではと考えている。ただし業務としてちょっとニッチなのと、利用するまでのハードルがかなり高いのは否めず、悩ましい気持ちである。
また、このエージェントを開発するにあたって苦労したあれこれを文章としてまとめる、ということで一人アドベントカレンダーをやりつつ、最終的にこれらの記事を本形式にまとめたりもした3。フレームワークを使わずLLMサービスのAPIだけでエージェントを作るという筋肉モリモリマッチョな実装の話だが、興味を持っていただけたらご笑覧ください。
2026年
2026年は社内外のデータの利活用をさらに促進する動きがあり、それを安全に保持、アクセスできるような運用やシステムを作るという取り組みにチャレンジするつもりである。法令やガイドライン、各事業の取り組み、セキュリティ要件などを折り込みながら設計・実装をするものなのでなかなかタフな仕事になりそうだが、それなりに楽しみだったりもする。
一方で最近やってみたいなという仕事がいろいろとあり、自分のキャリアと言うか人生についてもうっすら考えるタイミングなのかなという思いがちょっとある。ただ、プロダクト・コーポレートセキュリティをやっていくにあたっては個人的に今Ubieが日本で最もチャレンジしがいのある職場だと確信しており、そこはブレずにやっていくつもりである。むしろそういうセキュリティに興味がある方がいたら是非ご連絡ください。
ということで
皆様、今年も大変お世話になりました。良いお年をお過ごしください。
来年も各位どうぞよろしくおねがいします。